
En el post pasado hablamos sobre conceptos básicos de la programación reactiva, qué ventajas nos ofrece, y en qué ocasiones nos conviene beneficiarnos de ellas.
¿Qué temas vamos a tocar en éste post?
Pocos, pero con muchos conceptos internos que debemos tener en cuenta para entender programación reactiva en una implementación.
Vamos a hablar más en detalle sobre los actores que intervienen en éste paradigma e ir despejando el camino para implementar la librería reactiva de Java que veremos en la práctica: RxJava2.
- Patrón Observer: patrón de diseño sobre el cual se basan varios frameworks y librerías reactivas.
- Flujo de eventos y sus actores: veremos cómo se compone cada parte del mismo, sus particularidades y cómo interactúan entre sí.
- Backpressure: introducción y técnicas básicas para controlar el desborde de emisiones de datos.
- RxJava2: breve intro a la librería y sus definiciones respecto al patrón observer.
Sobre el patrón Observer
Si hacemos memoria al post anterior, comentamos que la programación reactiva se basa en el procesamiento de eventos y la propagación del cambio, es decir reaccionar a estímulos para modificar el entorno. Existe un patrón de diseño fuertemente ligado al concepto reactivo y sistemas basados en eventos: el Patrón Observer. ¿Su concepción básica?:
[…] es un patrón de diseño en el cual un objeto X, llamado Source, mantiene una lista de dependientes llamados Suscribers, a los cuales notifica automáticamente cuando se produce un cambio de estado. […]
¿Suena muy reactivo, no? 😉 Bien, existen muchos frameworks y librerías basados en este patrón de diseño y para varias tecnologías, tales como Akka Streams, Project Reactor o Reactive Extensions (mejor conocido como ReactiveX) del cual nos enfocaremos de acá en adelante.
¿Por qué enfocarnos en ReactiveX?*
*además de que es el único en el que tengo experiencia directa, ejem…
Es el set de librerías más conocidas, maduras, con muchas ventajas y provee implementaciones para una gran cantidad de lenguajes, de los cuales nos enfocaremos en Java. Pero antes que nada, necesitamos repasar un par de conceptos necesarios para entender su implementación.
Flujos de eventos y componentes involucrados
Como detallamos anteriormente, el patrón observer define una comunicación entre dos partes (subject-subscriber) por las cuales fluirá información. Esta comunicación se denomina Stream: una secuencia de eventos ordenadas en el tiempo.
Como ejemplo para visualizar las distintas partes del flujo, imaginemos una tubería por la que pasa un líquido en un solo sentido. En nuestra analogía, el líquido sería la información: un tipo específico de dato/objeto.

¿De dónde sale la información?
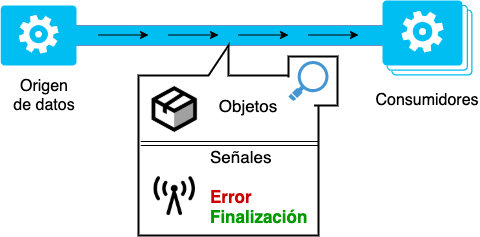
A través de un origen de datos (Source). Estas fuentes de información se encargan de transmitirla a través del flujo, sea que la generen ellos mismos o la reciban desde otra ubicación (otro source, por ejemplo).
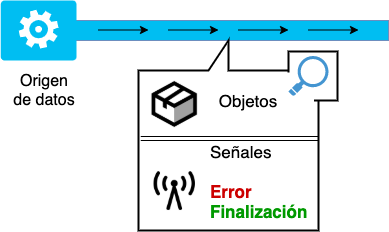
Los orígenes de datos pueden enviar adicionalmente a los objetos habituales, dos tipos de señales específicas que «cortan» el flujo de información enviado: de error si se produjo un problema en su funcionamiento, o de finalización en caso de que haya completado la emisión de datos y no tenga nada más que enviar.
¿Pero… falta alguien que reciba esa información, no?
Es cierto, los consumidores (Consumers) son el fin de nuestra hipotética tubería. Tienen dos funcionalidades: encargarse de recibir la información para procesarla y requerir del source más información a través de una señal en la medida que la necesiten.
💡 Recordemos que, dada la definición de la programación reactiva, las comunicaciones entre source y consumer son asíncronas: el consumer nunca sabe a ciencia cierta cuándo va a recibir la información del source al cual suscribe.
¡Alto! Nos falta algo…
Pareciera que ya tenemos todos los componentes del flujo, pero no es así. Nos queda definir un último actor implícito: la suscripción. Ésta decide cómo va a fluir la información, actuando de nexo entre source y el consumer. No será hasta que el consumidor se suscriba al origen de datos, que éste empiece a recibirlos.
❄️ Cold & 🔥 Hot sources
Ya sabiendo a qué nos referimos al hablar de source, hay dos variantes con las que nos vamos a topar al desarrollar y que nos definirán la forma en que emiten información y el modo en que nos comunicamos con ellos: cold y hot.
Los primeros, de tipo ❄️ cold, comenzarán a transmitir información al momento de que nos suscribamos a ellos. La emisión de datos la define cada consumer en la medida que necesita información en un estilo sincrónico, enviando una señal a través del flujo requiriendo más elementos para procesar. En otras palabras: regula su capacidad de trabajo.
Al crear una nueva suscripción a un source de este tipo, estaremos generando una nueva ejecución del mismo aislada del resto de los consumidores suscritos a éste, con los cuales no se comparte información (lo que se denomina Unicast).
En los sources de tipo 🔥 hot se comienza a transmitir información inmediatamente luego de que se crean (incluso antes de que nos suscribamos a ellos). A diferencia de los sources de tipo cold, los sources hot emiten información a su propio ritmo, y es responsabilidad de los consumers de arreglárselas para poder procesar toda esa información que se va generando.
En éste tipo de sources, se comparte la emisión de datos entre todos los consumidores suscritos a él (Multicast), de modo que al suscribirnos comenzaremos a recibir la información desde ese punto en adelante y todo lo ya emitido no lo tendríamos disponible.
¿Tenés un ejemplo?
Imaginate una peli nueva en Netflix que sale de estreno: te interesa y querés mirarla, entrás a la plataforma y comenzás a verla. Luego unos minutos más tarde, otro usuario en alguna parte de la ciudad decide mirar también la peli desde la comodidad de su casa y empieza a verla también desde el inicio. Cada uno comenzó a ver la película en distintos momentos, pero recibieron la misma cantidad de información. Es un caso de cold source.
Ahora, cambiemos a un canal de cable en el cual trasmiten un programa en vivo y en directo: si uno de los dos comienza a ver el programa luego de haber comenzado, se habrá perdido esos minutos y solo verá el contenido de ahí en adelante: podemos decir que es un caso de hot source, ambos consumers comparten el mismo generador de información.
Backpressure, o sobre cómo evitar que la cañería explote
Ok, hasta este punto nunca nos paramos a pensar en la frecuencia de la información producida desde un hot source: ¿qué pasaría si «inunda» o sobrepasa la capacidad del consumer de procesar la información? Estamos ante un caso en el que el source es más rápido que su consumer.
Para ser mas claros, imaginate un cuello de botella, donde la frecuencia de llegada de nuevos elementos es más rápida que la de salida. En este caso, estaríamos generando muchos más elementos de los que podemos procesar, incrementando el uso de memoria y pudiendo provocar un fallo total en caso de no controlarse.

💡 Es dificil predecir en qué momento un source va a producir más rápido que la capacidad de un consumer. Backpressure se trata de definir estrategias para decidir qué hacer con esa información “sobrante” momentáneamente para no saturar el sistema.
Para mantener la deseada resiliencia, debemos controlar de alguna forma la información entrante, a fin de no saturarnos con la información generada y afectar la performance de nuestro sistema.
¿Cómo podemos solucionar esto?
Podemos distinguir entre varios tipos de estrategias de backpressure que solucionarán los problemas de memoria acarreados, pero los 3 más comunes son los siguientes:
🗑 Drop: si llega nueva información hacia el consumer antes de que pida más, simplemente la desechamos.
🔝 Latest: fuerza al source a mantener solamente los N últimos registros emitidos, donde N es un número a definir por nosotros.
💾 Buffer: mantenemos en un buffer de memoria todos los registros que se fueron emitiendo para dejarlos disponibles al consumer cuando los requiera y luego liberarlos. Podríamos pensar que es la mejor opción, pero tiene un problema: almacenar toda esa información supone un gasto en memoria que se nos puede ir de las manos.
En el próximo post y para no marearnos, veremos con ejemplos prácticos las distintas técnicas de backpressure que tenemos a disposición para poder aplicar en nuestros streams.
💡Sí, puede que los controles de backpressure terminen escalando y afectando otros flujos hasta lograr una degradación en tiempos de respuesta, pero nos garantizan que el sistema siga funcionando bajo presión, a la vez que sirve de información para escalar en recursos y distribuir la carga de otra forma (elasticidad, otro de los pilares de los sistemas reactivos).
¡Todo listo! Esperá… ¿Qué era RxJava2?
RxJava2 es una implementación para java del proyecto ReactiveX: una librería enfocada a sistemas basados en eventos. Extiende del patrón Observer para soportar flujos de eventos (streams) al tiempo que nos abstrae de problemas como manejo de hilos a bajo nivel, sincronía, integridad de hilos y concurrencia.
📢 Nota de color: RxJava fué desarrollada por NETFLIX para satisfacer sus necesidades técnicas. Como todos sabemos, es una plataforma de streaming, que si recordamos es uno de los ejemplos donde más nos beneficiamos de aplicar programación reactiva dado los grandes volúmenes de información, concurrencia de usuarios, procesamiento y tiempos de respuesta requeridos.
Definiciones en RxJava2
Antes de pasar a la práctica del próximo post, veamos (a modo introductorio y para terminar de cerrar el tema) la correspondencias de cada uno de los actores del flujo en RxJava2.
Source/origen de datos ➡ Publisher
En RxJava2, un origen de datos implementa la interfaz Publisher.

Consumer/consumidor ➡ Subscriber
En el caso de éste actor, implementan la interfaz Subscriber. Si la analizamos, contamos con 4 funciones a implementar:
🙋♂️ OnNext: proceso a ejecutar al admitir la información proveniente de nuestro source.
🔒 OnSubscribe: ejecutado al momento de suscribirnos a un source determinado.
¿…y te acordás de las señales que podía enviar un source para cortar la comunicación hacia los consumers? Se envían ejecutando las siguientes funciones del subscriber que tiene asignado.
🚫 OnError: es la señal que nos envía el publisher cuando hay un error desde su lado.
✅ OnComplete: la señal que nos envía el origen de datos en caso de que no haya más información a enviar.

Subscription/Suscripción ➡ Subscription
No hay mucho que comentar acá, es la entidad que actúa de nexo entre nuestros consumers y nuestros sources.

Processor ➡ ¡Ey! ¡Este no lo vimos!
Y así es, pero lo detallamos brevemente al describir un source al especificar:
Estas fuentes de información se encargan de transmitirla a través del flujo, sea que la generen ellos mismos o la reciban desde otra ubicación (otro source, por ejemplo).
Si nos basamos en la última parte de esa afirmación, tenemos un source que a su vez se comporta como consumer 🤯. ¿Qué función tiene entonces este nuevo Processor? Justamente eso, representar orígenes de datos que, a la vez que emiten, también están pendientes de otros source de los cuales reciben información

Eso es todo de momento
¡Felicitaciones si llegaste hasta acá! 🙂 Para no extendernos demasiado en contenido, en el próximo post de la serie veremos como implementar cada uno de estos actores en una aplicación de ejemplo: haremos un pequeño monitor cardíaco que dispare alertas y tome decisiones en función de la frecuencia cardíaca del usuario.
Si tenés dudas, comentarios o te gustó el contenido ¡podés dejar un mensaje en la sección de abajo! 👇
¡Nos vemos antes del cierre de semana en un nuevo post de la serie!
